SQL Server のデータベースは、mdf ファイルと ldf ファイルから成っている。ldf ファイルはトランザクションログであり、肥大している場合は、サイズを小さくすることができる。
SQL Server Management Studio (ssms) を使って、トランザクションログのサイズを小さくする手順は以下のとおり。
1. SSMS で、対象となるデータベースで右クリックし、[タスク] - [圧縮] - [ファイル] とたどり、[ファイルの圧縮]ダイアログを開く。
2. [データベース ファイルおよびファイル グループ]の[ファイルの種類]で[ログ]を選ぶ。
3. [圧縮アクション]で[未使用領域の解放前にページを再構成する]を選び、[圧縮先のファイル]に圧縮後の目標サイズを入力する。ただし希望通りになるとは限らない。
4. [OK]ボタンを押す。
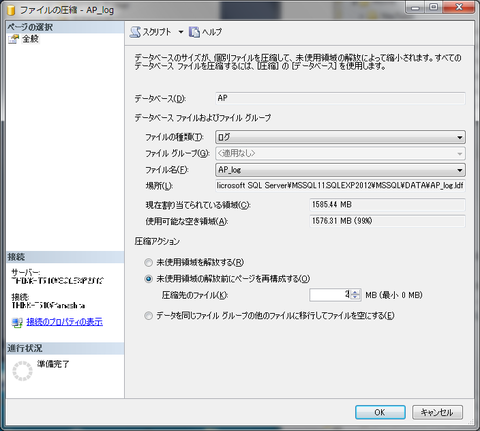
これでldf ファイルのサイズは小さくなる。ただし、実行中のトランザクションがあったりすると目標通りのサイズにならない場合もあるようだ。
以上。
SQL Server Management Studio (ssms) を使って、トランザクションログのサイズを小さくする手順は以下のとおり。
1. SSMS で、対象となるデータベースで右クリックし、[タスク] - [圧縮] - [ファイル] とたどり、[ファイルの圧縮]ダイアログを開く。
2. [データベース ファイルおよびファイル グループ]の[ファイルの種類]で[ログ]を選ぶ。
3. [圧縮アクション]で[未使用領域の解放前にページを再構成する]を選び、[圧縮先のファイル]に圧縮後の目標サイズを入力する。ただし希望通りになるとは限らない。
4. [OK]ボタンを押す。

これでldf ファイルのサイズは小さくなる。ただし、実行中のトランザクションがあったりすると目標通りのサイズにならない場合もあるようだ。
以上。